
當企業擁抱大型語言模型(LLM)的強大能力時,隨之而來的是一系列「甜蜜的煩惱」。開發團隊可能在不同專案中使用了來自 OpenAI, Anthropic, Google Vertex AI 的多種模型,導致 API 金鑰管理混亂、成本難以追蹤。更嚴重的是,缺乏統一的治理策略可能導致單一用戶或一個失控的腳本在一夜之間消耗上萬美元的預算,或是敏感資料在無監管的請求中外洩。
LiteLLM 作為一個輕量、高效能的 LLM 代理(Proxy/Gateway),其核心價值不僅僅在於簡化模型呼叫的路由、快取與備援,更在於它提供了一套強大而完整的企業級治理體系。這套體系涵蓋了從多租戶權限管理、精細預算控制到安全審計日誌的每一個環節,幫助企業將 LLM 的使用從混亂的「西部拓荒時代」帶入到安全、可控、可預測的「精細化運營時代」。
企業級治理的首要任務是建立清晰的組織結構與權限邊界。LiteLLM 透過一個直觀的四層式架構,完美實現了多租戶環境下的資源隔離與管理。
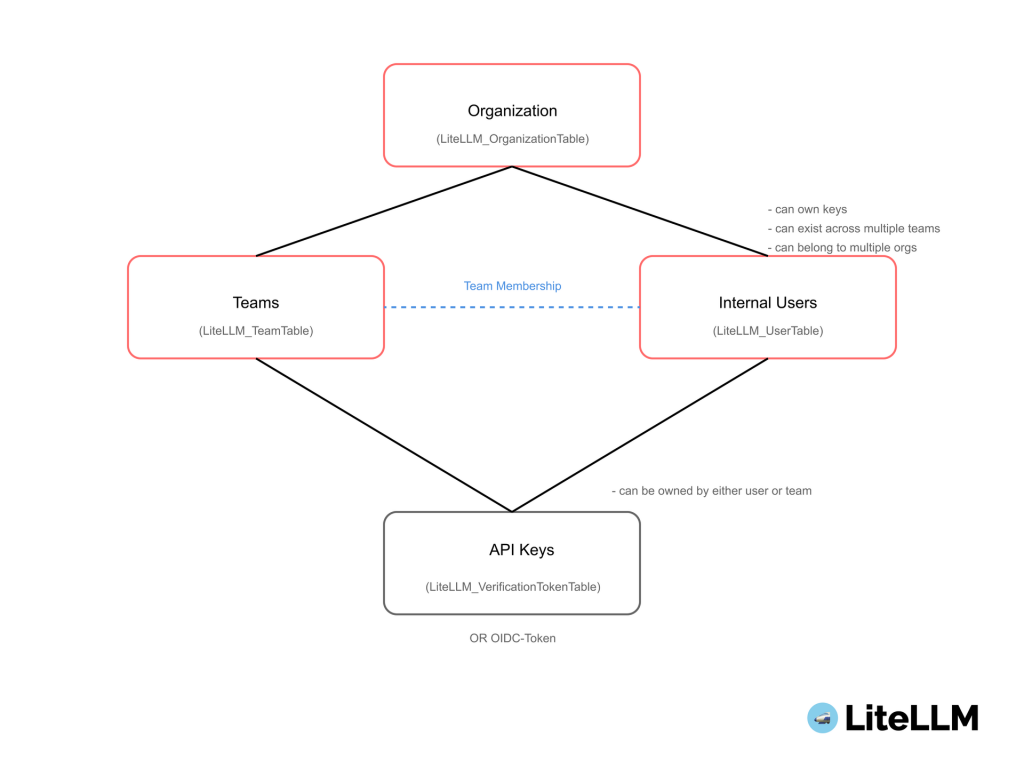
這個層級結構是 LiteLLM 治理的基石,每一層都有其明確的職責:
這張官方圖清晰地展示了 Organization, Team, User 之間的層級關係。
為了保障系統安全與職責分離,LiteLLM 內建了基於角色的存取控制(RBAC),主要角色包括:
這種設計確保了不同層級的管理者各司其職,既賦予了業務單位足夠的自主權,又保留了系統管理者的最終控制權。
成本是 LLM 落地最核心的考量之一。LiteLLM 提供了業界領先的多層級、週期性預算管理機制,能有效防止資源濫用和意外超支。
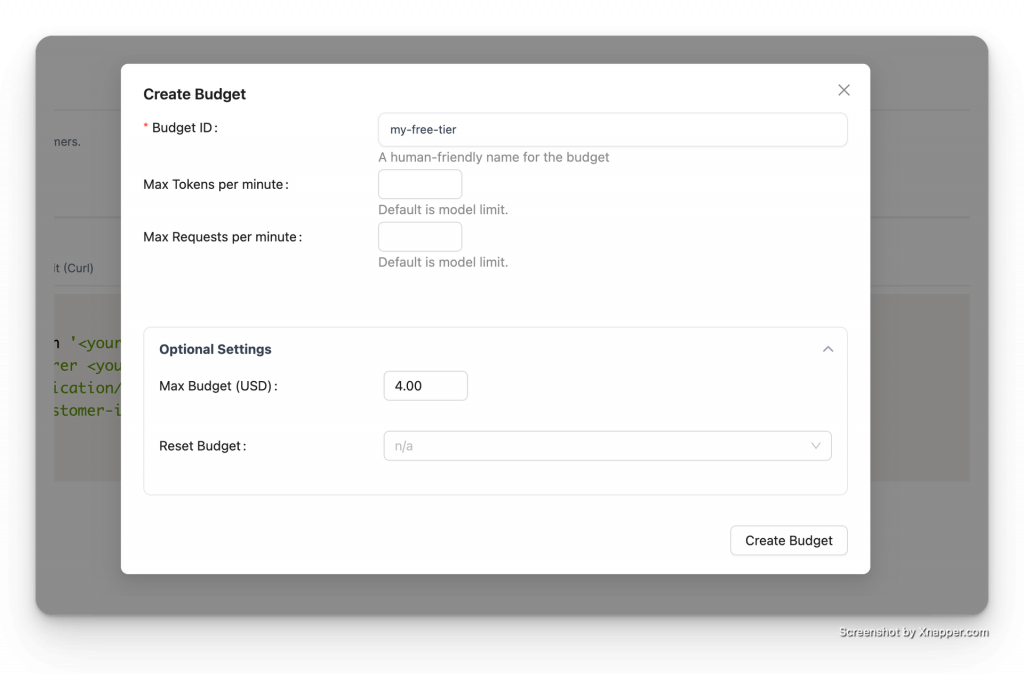
我們可以在幾乎所有層級設定預算,預算會從最具體的層級向上查找並應用:
範例:為團隊設定每月 $100 預算
在 config.yaml 中,可以這樣為一個團隊設定預算:
# config.yaml
proxy_settings:
...
teams:
- team_id: "marketing-team"
max_budget: 100.0 # 團隊每月預算 $100
budget_duration: "30d" # 預算週期為 30 天
budget_duration 參數讓預算管理變得自動化。我們可以設定 "1h" (小時), "30d" (30天) 等週期。LiteLLM 的背景任務會根據這個設定,在每個週期結束時自動重置預算,無需人工干預。
在團隊共享預算的基礎上,還可以為團隊內的個別成員設定消費上限 (max_budget_in_team),這對於控制團隊內高消耗用戶非常有用。
除了預算,速率限制是保障服務穩定性與控制成本的另一道重要防線。LiteLLM 提供了多維度的速率限制能力。
範例:為金鑰設定組合限流
# config.yaml
litellm_settings:
...
virtual_keys:
- api_key: "sk-user-1234"
tpm: 100000 # 每分鐘最多 100k tokens
rpm: 100 # 每分鐘最多 100 次請求
max_parallel_requests: 25 # 最多 25 個併發請求`
在生產環境中,我們通常會部署多個 LiteLLM Proxy 實例以實現高可用。LiteLLM 可以利用 Redis 在多個實例之間同步和共享速率限制的計數器。這確保了無論請求落在哪個實例上,總體的速率限制都是準確的,避免了單點故障和計數不準的問題。
最佳實踐:建議同時配置 TPM、RPM 和 Max Parallel Requests。
並非所有用戶或團隊都有權限使用所有模型,特別是像 GPT-4o 這樣昂貴的高階模型。LiteLLM 提供了精細的模型存取控制策略。
我們可以在金鑰、用戶或團隊層級透過 models 參數指定一個允許存取的模型白名單。
範例:限制金鑰只能使用特定模型
curl 'http://0.0.0.0:4000/key/generate' \
--header 'Authorization: Bearer <your-master-key>' \
--header 'Content-Type: application/json' \
--data-raw '{"models": ["gpt-3.5-turbo", "gpt-4"], "metadata": {"user": "ishaan@berri.ai"
當模型數量眾多時,逐一管理非常繁瑣。access_groups 允許我們將多個模型歸類為一個群組,然後將權限直接賦予群組。
範例:使用模型群組進行批量授權
# config.yaml
model_list:
- model_name: "gpt-4o"
litellm_params:
model: "openai/gpt-4o"
access_groups: ["premium-models"] # 將 gpt-4o 加入 premium 群組
- model_name: "claude-3-opus-20240229"
litellm_params:
model: "anthropic/claude-3-opus-20240229"
access_groups: ["premium-models"] # 將 opus 加入 premium 群組
這是一項強大的企業功能,允許使用 * 萬用字元進行更靈活的配置。例如,我們可以允許某個團隊使用所有 OpenAI 的模型 (openai/*),同時又明確禁止某個特定的高價模型。這在模型快速迭代的今天極其實用。
# config.yaml
model_list:
- model_name: openai/*
litellm_params:
model: openai/*
api_key: os.environ/OPENAI_API_KEY
model_info:
access_groups: ["default-models"]
- model_name: openai/o1-*
litellm_params:
model: openai/o1-*
api_key: os.environ/OPENAI_API_KEY
model_info:
access_groups: ["restricted-models"]
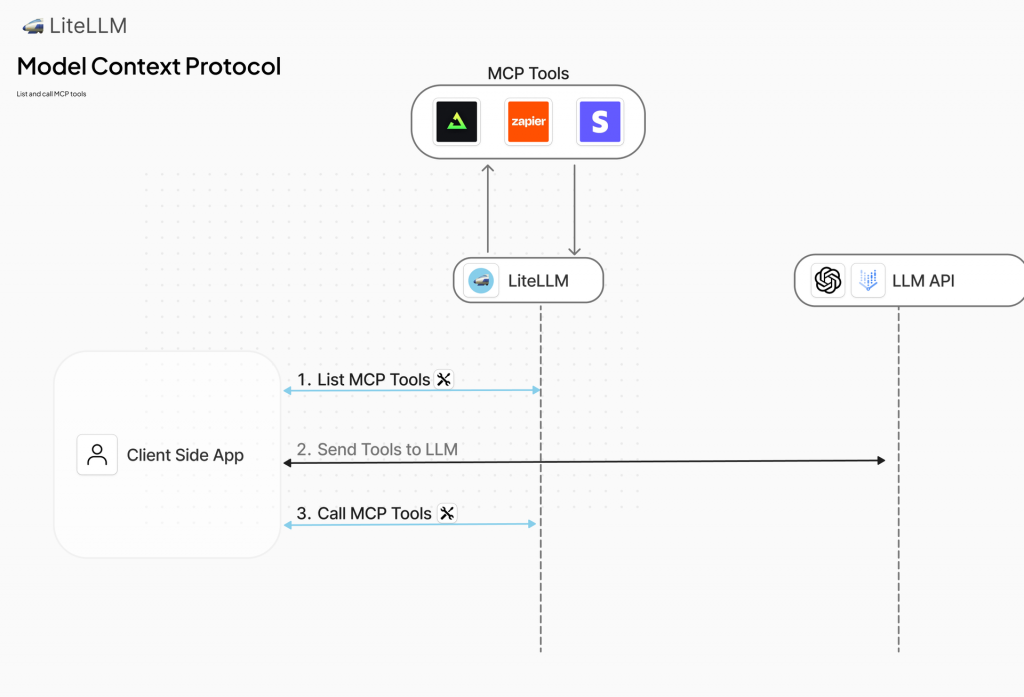
LiteLLM 的 MCP Server 管理功能設計用於企業級環境,特別針對多團隊使用多個 MCP Server 時的常見痛點,如憑證管理混亂、權限不一致和整合複雜性。透過 LiteLLM Proxy 作為 MCP Gateway,它提供一個集中化的解決方案,讓管理者能輕鬆註冊多個 MCP Server(例如 GitHub MCP 或 Zapier MCP),並透過 UI 的 "MCP Servers" 介面或 config.yaml 檔案進行配置,例如:
mcp_servers:
github_mcp:
url: "https://api.githubcopilot.com/mcp"
auth_type: oauth2
allowed_tools: ["list_tools", "call_tool"]
這避免了團隊各自維護伺服器的混亂,轉而使用統一入口點,支援 Streamable HTTP、SSE 和 stdio 等傳輸方式,讓客戶端(如 Cursor IDE)只需簡單 JSON 配置即可存取所有工具,而無需直接暴露內部 URL 或憑證。
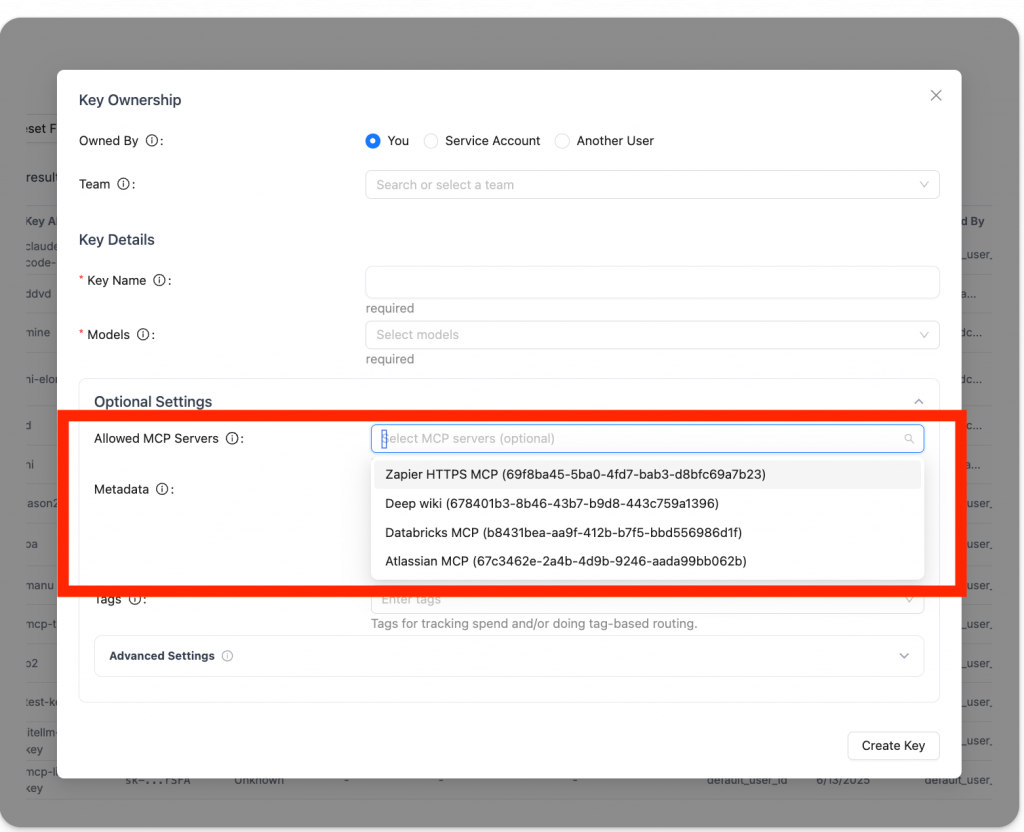
實務應用中,這有助於企業多租戶場景,例如開發團隊僅存取 GitHub MCP 進行程式碼工具呼叫,而行銷團隊限用 Zapier MCP 自動化工作流。官方文檔強調,如果未指定伺服器,所有註冊伺服器均可存取,但透過權限過濾(如 allowed_tools 或 disallowed_tools),管理者能精確控制,確保安全與合規。總體而言,這不僅解決了多團隊的混亂,還強化了統一管理,支援無縫整合到任何 LiteLLM 支援的模型中。
| 功能 | 描述 | 多團隊益處 | 治理範例 |
|---|---|---|---|
| 集中註冊 | UI 或 config.yaml 新增 MCP Server | 避免憑證散亂 | 新增 GitHub MCP 並設定 auth_type |
| 統一端點 | /mcp/ 作為單一入口 | 簡化客戶端配置 | Cursor IDE 使用 Bearer Token 存取 |
| 權限設定 | 按 Key/Team/Org 限制伺服器 | 隔離團隊存取 | 只允許 "dev_group" 給特定使用者 |
| 命名空間 | URL 或 Header 過濾伺服器 | 指定特定存取 | /mcp/github 只暴露 GitHub 工具 |
對於 SaaS 服務或對外提供 AI 功能的應用,我們需要追蹤和管理成千上萬的終端客戶 (End-Users),而不是內部開發者。為每個終端客戶都創建一個 API Key 是不現實的。
LiteLLM 允許我們在發送 /chat/completions 請求時,傳入一個 user 參數(這也是 OpenAI API 的標準參數)。LiteLLM 會自動將該次請求的成本和用量記錄到這個 user ID 上,而無需為其創建虛擬金鑰。
範例:在 API 請求中追蹤終端客戶
import openai
client = openai.OpenAI(
api_key="sk-your-litellm-proxy-key",
base_url="http://localhost:4000"
)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "Hello world!"}],
user="customer-123-free-tier" # LiteLLM 會將成本計入 'customer-123-free-tier'
)
如果超出預算後,我們將會看到類似的以下錯誤:
{
"error":
{
"message":"Budget has been exceeded: User client-001 has exceeded their budget. Current spend: 0.0008869999999999999; Max Budget: 0.0001",
"type":"auth_error",
"param":"None",
"code":401
}
}
我們可以預先透過管理 API 為 customer-123-free-tier 這樣的用戶 ID 設定預算。更進一步,我們可以設定一個全域預設客戶預算 (litellm.max_end_user_budget)。這樣,任何新的、從未見過的 user ID 發起請求時,LiteLLM 會自動為其創建一個預設的預算,極大地簡化了新用戶註冊和試用流程的管理。
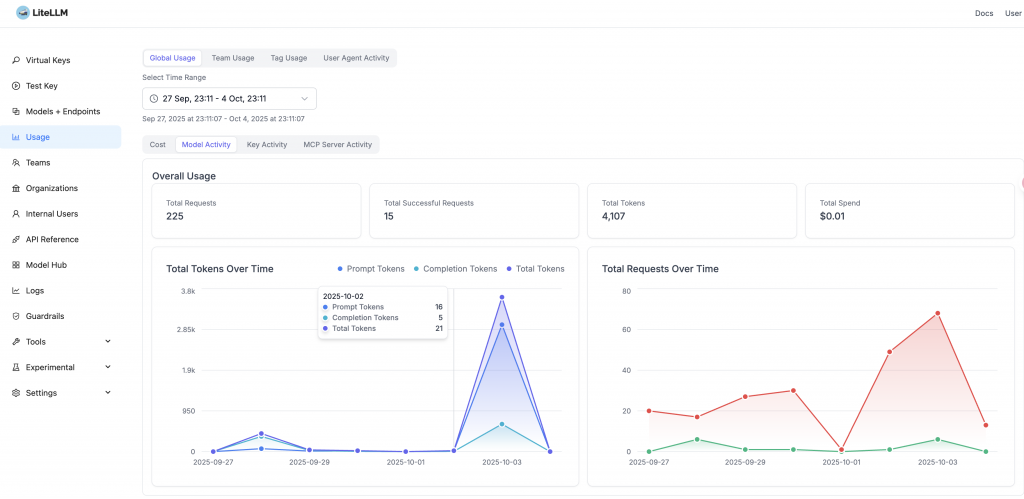
透明、即時的成本可見性是治理的基礎。
LiteLLM 會自動根據內建的 模型成本對照表 計算每個請求的精確成本,並在回應的 Headers 中返回 x-litellm-response-cost。這讓我們的應用程式可以即時了解並記錄每筆呼叫的花費。
curl -i -sSL --location 'http://0.0.0.0:4000/chat/completions' \
--header 'Authorization: Bearer sk-1234' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "what llm are you"}]
}' | grep 'x-litellm'
此時,我們在 Response Header 可以即時得到此輪對話的花費成本:
x-litellm-call-id: b980db26-9512-45cc-b1da-c511a363b83f
x-litellm-model-id: cb41bc03f4c33d310019bae8c5afdb1af0a8f97b36a234405a9807614988457c
x-litellm-model-api-base: https://x-example-1234.openai.azure.com
x-litellm-version: 1.40.21
x-litellm-response-cost: 2.85e-05
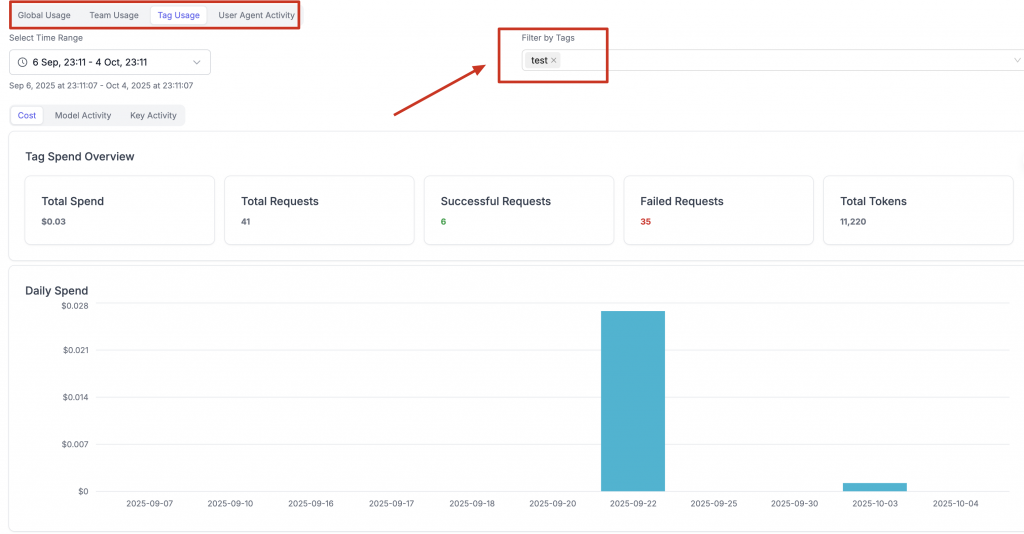
為了實現更細粒度的成本歸因,LiteLLM 支援在虛擬金鑰的 metadata 中添加 tags。例如,我們可以為一個金鑰打上 {"project": “test", "env": "production"} 的標籤。所有使用該金鑰產生的費用都會與這些標籤關聯,讓我們可以輕鬆地在後端分析出 test 專案在生產環境的總花費,實現了企業級的成本中心管理。
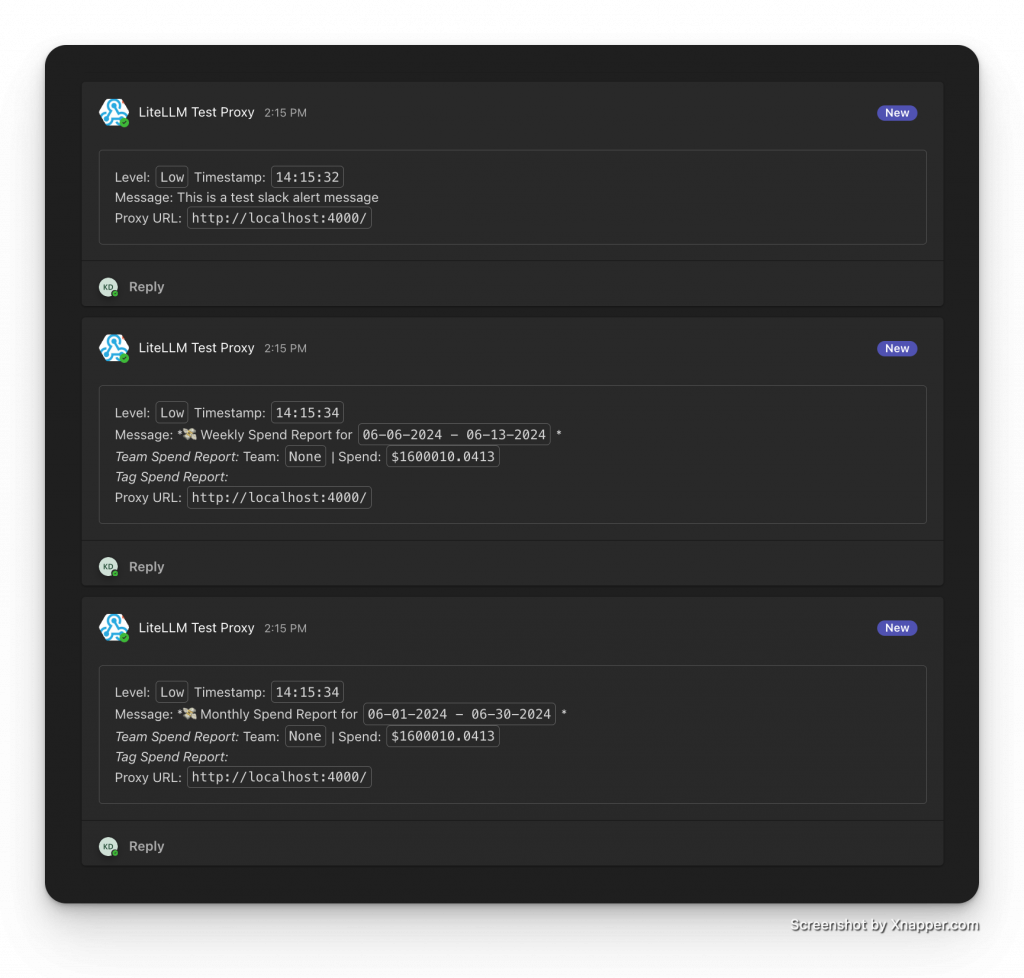
及時發現問題才能及時止損。LiteLLM 提供了豐富的告警機制,能透過多種通道通知。
除了達到預算上限(硬限制)時阻止請求,還可以設定一個 soft_budget(例如預算的80%)。當費用達到這個閾值時,LiteLLM 會提前發出告警,讓我們有時間在服務被中斷前採取行動(如增加預算)。
我們可以輕鬆配置將告警發送到:
範例:在 config.yaml 中配置 Slack 告警
`# config.yaml
litellm_settings:
alerting: ["slack"] # 啟用 Slack 告警
alerting_params:
slack_webhook_url: "your-slack-webhook-url"`
LiteLLM 支援多種告警事件,包括但不限於:
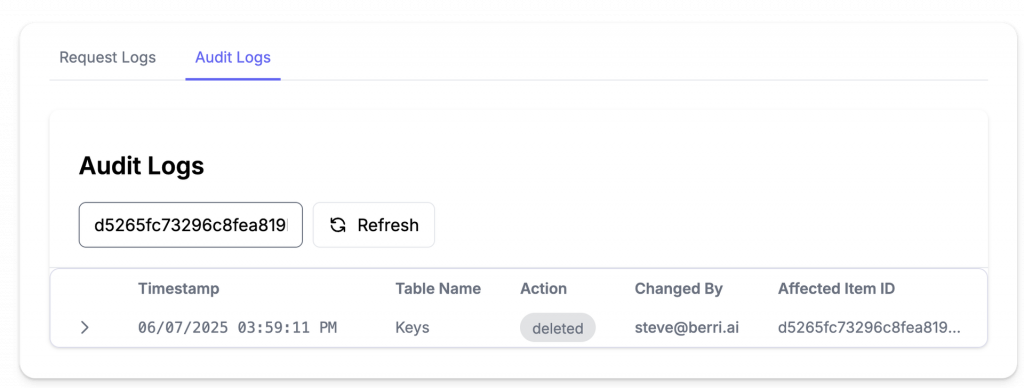
在對安全性和合規性要求嚴格的企業中,追蹤所有管理操作的變更是至關重要的。
審計日誌會詳細記錄:
這提供了完整的變更追蹤鏈,無論是出於安全調查還是合規稽核的目的,都能提供不可否認的證據。
預設情況下,LiteLLM 不會記錄請求的 prompts 和 responses 內容,以保護資料隱私。 同時,我們可以設定日誌的保留週期 (maximum_spend_logs_retention_period),LiteLLM 會自動清理過期的日誌,防止資料庫無限膨脹。
綜合以上功能,我們可以總結出一些治理策略的最佳實踐。
LiteLLM 不僅僅是一個 API 統一入口,它提供了一整套從頂層設計到底層實現的完整 LLM 治理框架。透過其靈活的分層架構、精細的預算與速率限制、強大的存取控制和全面的審計日誌,企業可以充滿信心地大規模部署和應用 LLM,同時將成本、安全與合規風險牢牢掌控在手中。無論是初創公司還是大型企業,LiteLLM 都為駕馭 AI 浪潮提供了不可或缺的羅盤與船錨。
References:

